

Node.js Performance #2: Object vs Map
An In-depth Comparison: Understanding the Performance and Efficiency of Object vs Map in JavaScript's V8 Engine



Photo by Ferenc Almasi on Unsplash
Intro
In JavaScript, two major data structures are used to store key-value pairs: Objects and Maps. Both have their unique characteristics, benefits, and use cases, but they serve the same general purpose – to store data in a key-value format.
Objects are the fundamental blocks of JavaScript and have been around since its inception. They offer a straightforward way to create and manipulate named properties, which can be either simple values, other objects, or functions. Objects are ideal for scenarios when you know the keys in advance, as they provide a simple and efficient way to structure data.
On the other hand, Maps are a relatively newer feature introduced in ES6. They maintain the insertion order of elements, making them excellent for scenarios where data order matters. Maps also allow more key types than objects, broadening their usability.
Understanding the differences between these two data structures is crucial for effective JavaScript programming. It can greatly improve your code's performance and make it easier to manage and manipulate data.
So today, we'll talk about Object vs Map.
Brief history
Before ES6 introduced Maps, JavaScript Objects were the main choice for key-value storage. They were versatile, but had limitations. For example, they only accepted strings and symbols as keys, which limited their use. There are no methods for determining the map size for constant time, issues with iteration, and potential name collisions with object’s own properties.
const someMap = { a: 1, b: 2 };
// Object.keys takes O(n) time
const size = Object.keys(someMap).length;
// for .. in will return inherited properties
Object.prototype.someField = "some value";
const someOtherMap = { c: 3 };
for (const key in someOtherMap) {
console.log(key); // 'c', 'someField'
}
// better to use Object.keys(), but again it requires O(n) time to create array with keys
for (const key of Object.keys(someOtherMap)) {
console.log(key); // 'c'
}
// it's possible to accidently shadow method from prototype
const methodsResultMap = { someMethod: true };
methodsResultMap["hasOwnProperty"] = false;
// Uncaught TypeError: methodsResultMap.hasOwnProperty is not a function
methodsResultMap.hasOwnProperty("someMethod");
Despite these drawbacks, Objects were often used for key-mapping storage because there were no other options. They provided a simple way to create and handle named properties. Plus, they've been part of JavaScript since the beginning, so developers were used to them. And so much accustomed to them, that now Map is still way underused.
const someMap = new Map([
['a', 1],
['b', 2]
]);
But how can we compare them in terms of performance? Is an Object still overall better than a Map, and are there valuable objections to using a Map? Let's find out.
Performance
Before taking any performance benchmarks, we need to answer the question: What should we benchmark?
So, I would choose the five main operations with a map: filling the map with values, checking if a value exists, retrieving a particular element by key, iterating through all elements, and clearing the map. At least, these are my general operations with map-like data structures.
Data preparation
To avoid any correlations between data and Object/Map instances, we need to ensure that we're using the same data for both implementations. For our benchmark scenarios, I'll prepare two different arrays: one for keys and one for values.
For keys, there will be two variants: strings of random lengths and fixed-size hash-like strings:
const keysDefault = ["aa", "aabbb", "aacb", ... ];
const keysHashes = ["c89efdaa54c0f20c7adf612882df0950f5a951637e0307cdcb4c672f298b8bc6", "ad7c5bef027816a800da1736444fb58a807ef4c9603b7848673f7e3a68eb14a5", ...];
For values, I'll also use two sets: random strings and objects with the same structure but with different property values (to simulate TypeScript scenarios like Map<String, SomeType>):
const valuesDefault = ["aa", "aabbb", "aacb", ... ];
const valuesObject = [
{
a: "aaa",
b: "aabbb",
},
{
a: "aacb",
b: "bbbccc",
},
...
]
As always, feel free to grab the sources and play with your scenarios.
Filling the map with values
As we decide to use arrays for keys and values in the case of an Object, the code will be as follows:
function fillObjectMap(keys, values) {
const result = {};
for (let i = 0; i < keys.length; i++) {
result[keys[i]] = values[i];
}
return result;
}
And for Map:
function fillNativeMap(keys, values) {
const result = new Map();
for (let i = 0; i < keys.length; i++) {
result.set(keys[i], values[i]);
}
return result;
}
Checking if a value exists or not
For checking values, I'll use an array with 50% of existing keys and 50% of random keys that don't exist.
For Object:
for (let i = 0; i < keysToCheck.length; i++) {
result[i] = objectMap.hasOwnProperty(keysToCheck[i]);
}
For Map:
for (let i = 0; i < keysToCheck.length; i++) {
result[i] = nativeMap.has(keysToCheck[i]);
}
Getting a particular element by key
For getting values the same array as for checking will be used.
For Object:
for (let i = 0; i < keysToGet.length; i++) {
result[i] = objectMap[keysToGet[i]];
}
For Map:
for (let i = 0; i < keysToGet.length; i++) {
result[i] = nativeMap.get(keysToGet[i]);
}
Iterating through all elements
Usually, in my daily work, I need to iterate through keys and values at the same time, so let's use the same pattern here.
For Object:
for (const [key, value] of Object.entries(objectMap)) {
result.push([key, value]);
}
For Map:
for (const [key, value] of nativeMap.entries()) {
result.push([key, value]);
}
Clearing the map
Since Object doesn't have methods to clear all keys, there is no reason to benchmark the clear method on Map. Instead, we'll compare the delete object[key] operator with the delete method.
Object:
for (let i = 0; i < keysToDelete.length; i++) {
delete objectMap[keysToDelete[i]];
}
Map:
for (let i = 0; i < keysToDelete.length; i++) {
nativeMap.delete(keysToDelete[i]);
}
Benchmarking
So, let's benchmark our cases to see which one, Object or Map, is faster.
As with the previous time, the approach is as follows:
Generate input data;
Do some warmup: run a couple of dozen loops to give the JS engine time to compile and optimize the methods;
Run the benchmark: again, run a couple of dozen loops with the method calls, but now with time measurement;
Check the results.
The source code for the benchmarking can be found here.
Results
Since we have a relatively large amount of data, to minimize variables such as GC, I'll conduct four iterations for each experiment (2 in the calling order of object → native, 2 – native → object to average GC times). We have a lot of data, so let's go through the numbers.
Filling the map with values
Let's start with the default variant, where the key and value are random strings with A-Za-z characters with a typical length ranging from 3 to 14.
| Size | Iteration # | Object (ms) | Map (ms) | Diff (%) |
| 100 | 1 | 0,864 | 0,16 | 540% |
| 2 | 0,811 | 0,162 | 501% | |
| 3 | 0,788 | 0,179 | 440% | |
| 4 | 0,858 | 0,188 | 456% | |
| avg | 0,830 | 0,172 | 482% | |
| 1_000 | 1 | 7,315 | 0,786 | 931% |
| 2 | 7,281 | 0,768 | 948% | |
| 3 | 5,859 | 1,442 | 406% | |
| 4 | 5,89 | 1,404 | 420% | |
| avg | 6,586 | 1,100 | 599% | |
| 100_000 | 1 | 685,451 | 133,766 | 512% |
| 2 | 696,037 | 134,949 | 516% | |
| 3 | 611,193 | 172,48 | 354% | |
| 4 | 626,051 | 170,917 | 366% | |
| avg | 654,683 | 153,028 | 428% | |
| 200_000 | 1 | 1663,113 | 282,725 | 588% |
| 2 | 1704,195 | 283,309 | 602% | |
| 3 | 1485,016 | 369,127 | 402% | |
| 4 | 1498,019 | 372,934 | 402% | |
| avg | 1587,586 | 327,024 | 485% | |
| 500_000 | 1 | 5080,894 | 921,806 | 551% |
| 2 | 5057,104 | 934,713 | 541% | |
| 3 | 4573,426 | 1236,958 | 370% | |
| 4 | 4614,194 | 1236,319 | 373% | |
| avg | 4831,405 | 1082,449 | 446% |
Okay, it appears that the order of calls makes sense, albeit not entirely. We can also say that the relationship between size and time is almost linear, so our measurements seem logical because the insert operation cost in a map is O(1).
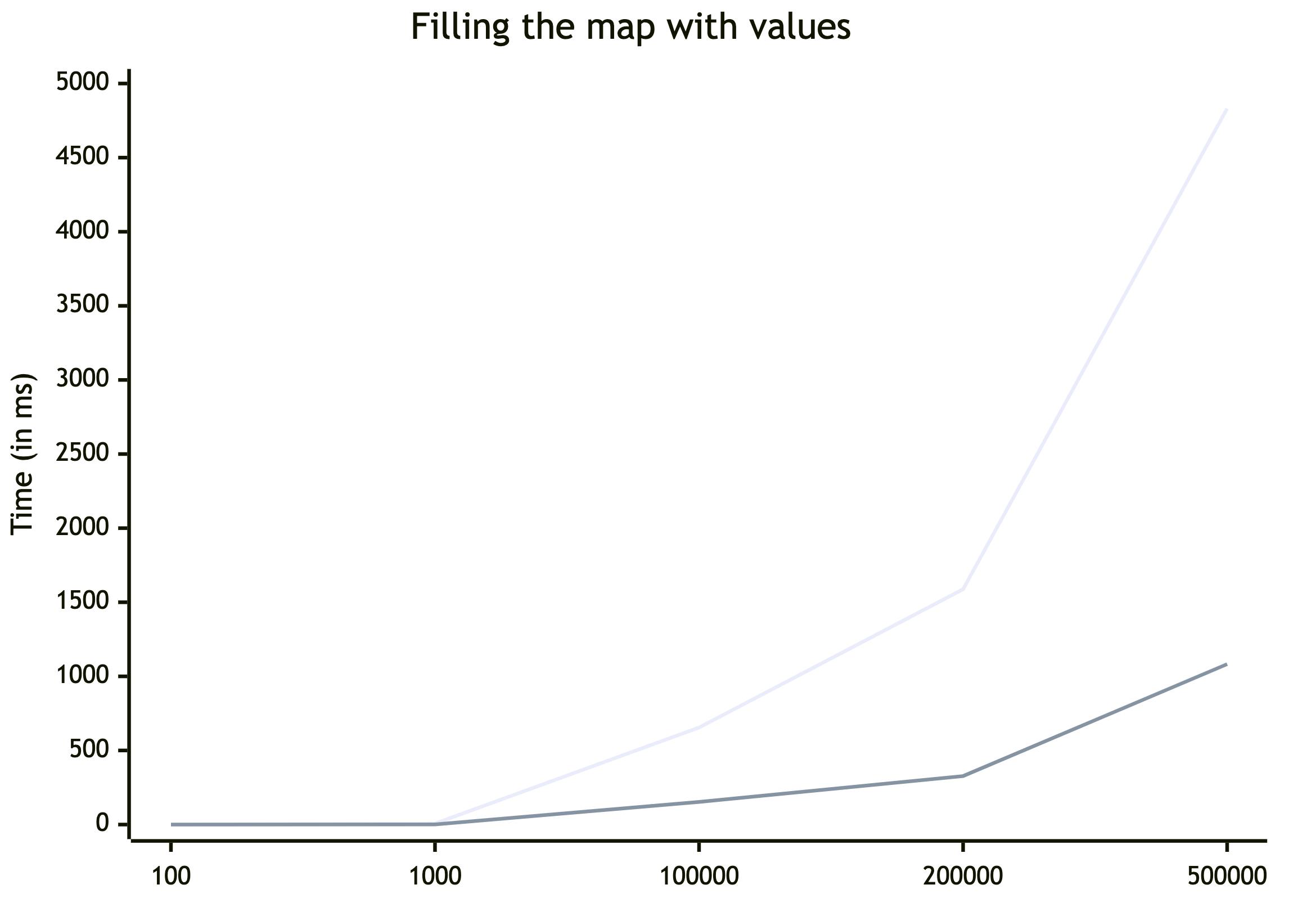
In general, Map is ~4.5-5 times faster for insertion. Let's examine the changes if we use a string with 256-bit hash as a key.
| Size | Iteration # | Object (ms) | Map (ms) | Diff (%) |
| 100 | 1 | 1,217 | 0,097 | 1255% |
| 2 | 1,197 | 0,093 | 1287% | |
| 3 | 0,729 | 0,356 | 205% | |
| 4 | 0,689 | 0,343 | 201% | |
| avg | 0,958 | 0,222 | 431% | |
| 1_000 | 1 | 10,067 | 0,673 | 1496% |
| 2 | 10,071 | 0,683 | 1475% | |
| 3 | 5,575 | 3,037 | 184% | |
| 4 | 5,575 | 3,068 | 182% | |
| avg | 7,822 | 1,865 | 419% | |
| 100_000 | 1 | 1018,072 | 134,154 | 759% |
| 2 | 1013,994 | 132,808 | 764% | |
| 3 | 661,416 | 327,258 | 202% | |
| 4 | 656,942 | 327,738 | 200% | |
| avg | 837,606 | 230,490 | 363% | |
| 200_000 | 1 | 2438,607 | 317,095 | 769% |
| 2 | 2359,677 | 305,373 | 773% | |
| 3 | 1642,642 | 725,101 | 227% | |
| 4 | 1692,786 | 729,309 | 232% | |
| avg | 2033,428 | 519,220 | 392% | |
| 500_000 | 1 | 6770,692 | 1107,551 | 611% |
| 2 | 6768,21 | 1117,992 | 605% | |
| 3 | 4764,669 | 2403,295 | 198% | |
| 4 | 4793,974 | 2387,991 | 201% | |
| avg | 5774,386 | 1754,207 | 329% |
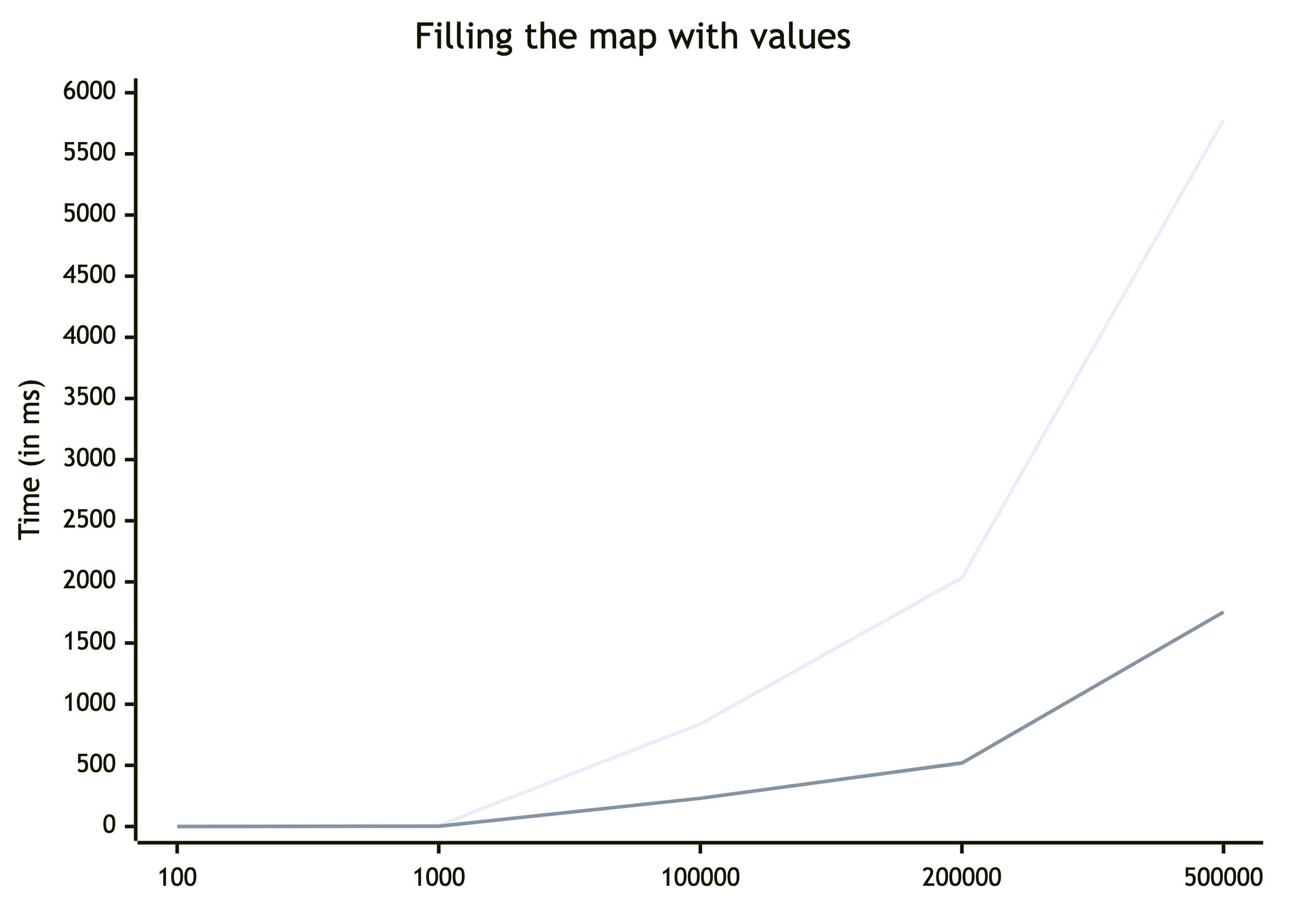
Still, on average, Map is around ~4 times faster, but now keys require much more memory and I suspect that degradation is related to GC work or other memory-related stuff. We'll examine memory consumption later. I won't add tables and charts for the case when values are objects, because there's nothing special there. Same trends. So, let's move on.
Checking if a value exists or not
Since existence check is also O(1) in a map, I don't expect any drastic difference in performance here.
| Size | Iteration # | Object (ms) | Map (ms) | Diff (%) |
| 100 | 1 | 0,125 | 0,094 | 133% |
| 2 | 0,117 | 0,092 | 127% | |
| 3 | 0,109 | 0,115 | 95% | |
| 4 | 0,101 | 0,111 | 91% | |
| avg | 0,113 | 0,103 | 110% | |
| 1_000 | 1 | 1,14 | 0,928 | 123% |
| 2 | 1,1 | 0,867 | 127% | |
| 3 | 0,952 | 0,923 | 103% | |
| 4 | 0,911 | 0,876 | 104% | |
| avg | 1,026 | 0,899 | 114% | |
| 100_000 | 1 | 149,636 | 125,14 | 120% |
| 2 | 146,882 | 123,977 | 118% | |
| 3 | 148,797 | 124,776 | 119% | |
| 4 | 146,461 | 125,339 | 117% | |
| avg | 147,944 | 124,808 | 119% | |
| 200_000 | 1 | 392,979 | 331,654 | 118% |
| 2 | 387,818 | 334,597 | 116% | |
| 3 | 357,272 | 348,509 | 103% | |
| 4 | 359,373 | 360,486 | 100% | |
| avg | 374,361 | 343,812 | 109% | |
| 500_000 | 1 | 1209,261 | 1335,896 | 91% |
| 2 | 1197,811 | 1317,791 | 91% | |
| 3 | 1069,471 | 1375,362 | 78% | |
| 4 | 1065,386 | 1405,126 | 76% | |
| avg | 1135,482 | 1358,544 | 84% |
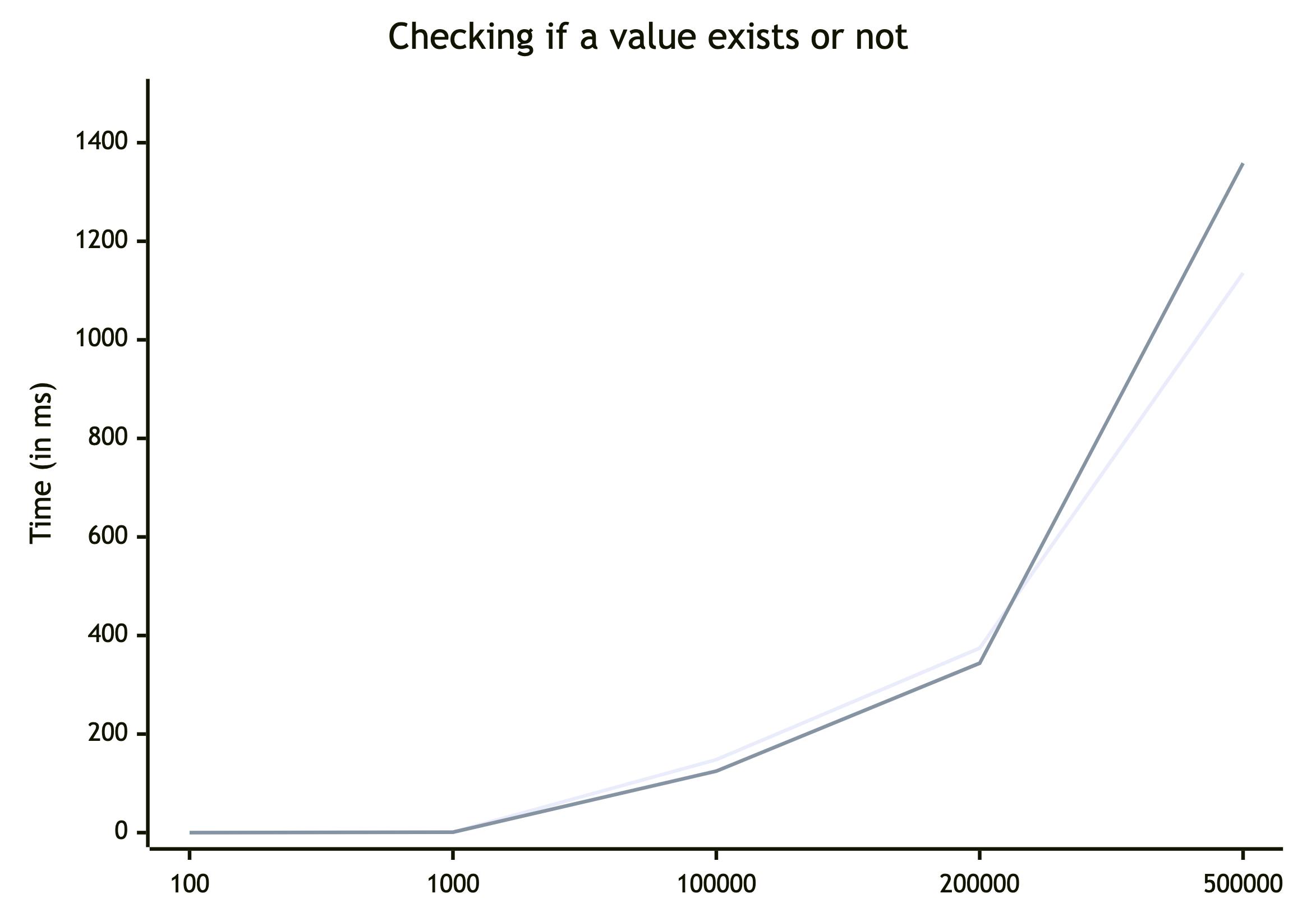
From the values, we can see that on average, Map is only 7% faster. However, the larger the size, the smaller the difference, until eventually, for 500k, Object is faster. So, I would say that for checking Map and Object show the same performance in general. Hashed strings and objects-as-values don't change the overall behaviour, so I'll skip them.
Getting a particular element by key
Again getting an element is like existence check also O(1) in a map and we should get the same results.
| Size | Iteration # | Object (ms) | Map (ms) | Diff (%) |
| 100 | 1 | 0,351 | 0,068 | 516% |
| 2 | 0,333 | 0,061 | 546% | |
| 3 | 0,276 | 0,115 | 240% | |
| 4 | 0,273 | 0,107 | 255% | |
| avg | 0,308 | 0,088 | 351% | |
| 1_000 | 1 | 2,593 | 0,564 | 460% |
| 2 | 2,813 | 0,586 | 480% | |
| 3 | 2,068 | 0,938 | 220% | |
| 4 | 2,082 | 0,946 | 220% | |
| avg | 2,389 | 0,759 | 315% | |
| 100_000 | 1 | 367,051 | 95,139 | 386% |
| 2 | 366,478 | 94,566 | 388% | |
| 3 | 320,579 | 135,487 | 237% | |
| 4 | 322,573 | 137,071 | 235% | |
| avg | 344,170 | 115,566 | 298% | |
| 200_000 | 1 | 920,408 | 266,668 | 345% |
| 2 | 920,291 | 279,06 | 330% | |
| 3 | 790,696 | 391,702 | 202% | |
| 4 | 771,922 | 392,069 | 197% | |
| avg | 850,829 | 332,375 | 256% | |
| 500_000 | 1 | 2778,005 | 1019,075 | 273% |
| 2 | 2792,232 | 1036,136 | 269% | |
| 3 | 2354,46 | 1462,906 | 161% | |
| 4 | 2338,436 | 1562,371 | 150% | |
| avg | 2565,783 | 1270,122 | 202% |
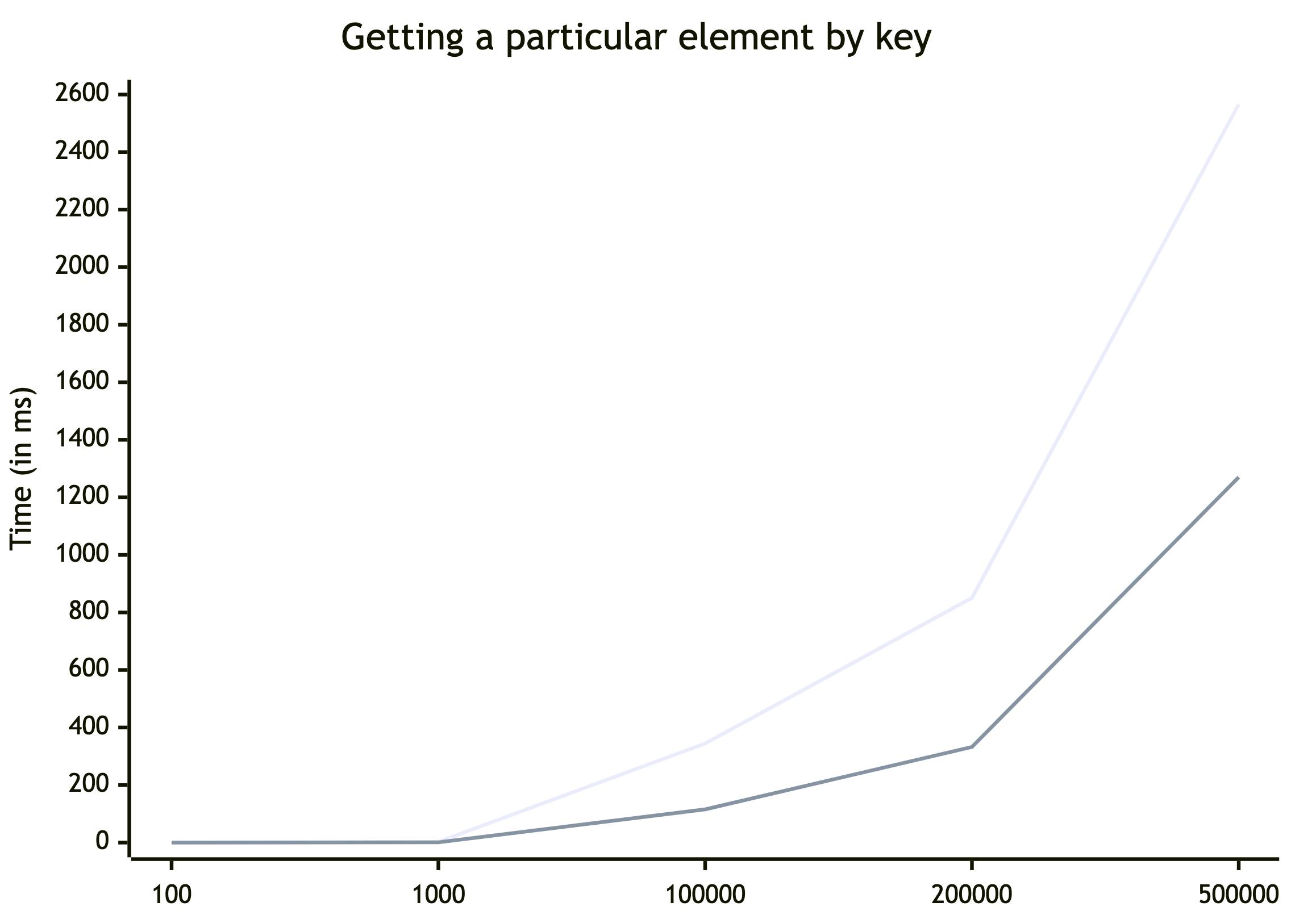
Surprise, surprise! I thought we would get the same results as for the existence check, but Map outperforms Object here by approximately 2.8 times. If we take a look at Map times, we will notice that the has() and get() methods take almost the same time, while hasOwnProperty() is much faster than just object[key].
Iterating through all elements
It's expected that Map will be a clear winner here, because Object.entries takes O(n) time and we need to iterate through all elements – again O(n) time. Meanwhile, Map.prototype.entries() will return an iterator. But let's take a look at the numbers to prove our hypothesis.
| Size | Iteration # | Object (ms) | Map (ms) | Diff (%) |
| 100 | 1 | 0,359 | 0,028 | 1282% |
| 2 | 0,355 | 0,028 | 1268% | |
| 3 | 0,359 | 0,054 | 665% | |
| 4 | 0,342 | 0,041 | 834% | |
| avg | 0,354 | 0,038 | 937% | |
| 1_000 | 1 | 3,414 | 0,192 | 1778% |
| 2 | 3,31 | 0,191 | 1733% | |
| 3 | 3,327 | 0,194 | 1715% | |
| 4 | 3,301 | 0,187 | 1765% | |
| avg | 3,338 | 0,191 | 1748% | |
| 100_000 | 1 | 526,024 | 44,084 | 1193% |
| 2 | 495,094 | 43,956 | 1126% | |
| 3 | 560,781 | 55,135 | 1017% | |
| 4 | 563,52 | 47,201 | 1194% | |
| avg | 536,355 | 47,594 | 1127% | |
| 200_000 | 1 | 1197,036 | 70,074 | 1708% |
| 2 | 1191,576 | 71,35 | 1670% | |
| 3 | 1334,452 | 138,176 | 966% | |
| 4 | 1321,185 | 125,732 | 1051% | |
| avg | 1261,062 | 101,333 | 1244% | |
| 500_000 | 1 | 4482,695 | 404,581 | 1108% |
| 2 | 4492,36 | 401,158 | 1120% | |
| 3 | 4497,207 | 277,578 | 1620% | |
| 4 | 4474,672 | 249,699 | 1792% | |
| avg | 4486,734 | 333,254 | 1346% |
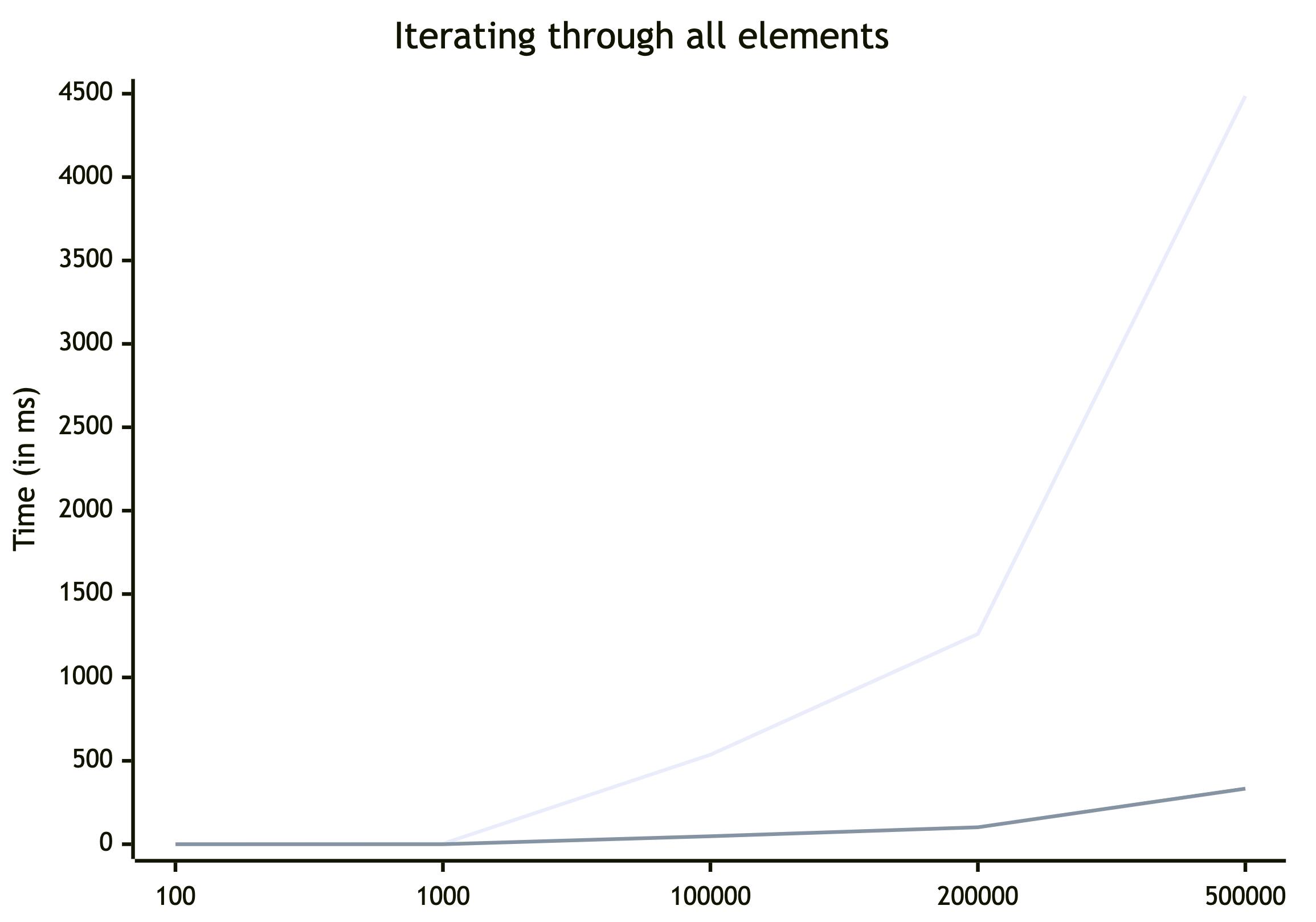
Personally, I had hoped to see more linear characteristics of Object, but it is what it is. Map is ~12.8 times (!!!) faster. Even if O(n) + O(n) for Object is still O(n), the numbers don’t lie.
Clearing the map
Finally, the last operation - deletion. Again, it's algorithmic constant time. Should it be straightforward, or not?
| Size | Iteration # | Object (ms) | Map (ms) | Diff (%) |
| 100 | 1 | 0,129 | 0,096 | 134% |
| 2 | 0,118 | 0,092 | 128% | |
| 3 | 0,115 | 0,104 | 111% | |
| 4 | 0,115 | 0,102 | 113% | |
| avg | 0,119 | 0,099 | 121% | |
| 1_000 | 1 | 0,973 | 0,686 | 142% |
| 2 | 0,968 | 0,695 | 139% | |
| 3 | 0,947 | 0,74 | 128% | |
| 4 | 0,995 | 0,792 | 126% | |
| avg | 0,971 | 0,728 | 133% | |
| 100_000 | 1 | 128,33 | 96,55 | 133% |
| 2 | 130,588 | 97,79 | 134% | |
| 3 | 130,537 | 98,16 | 133% | |
| 4 | 129,546 | 100,045 | 129% | |
| avg | 129,750 | 98,136 | 132% | |
| 200_000 | 1 | 303,532 | 244,151 | 124% |
| 2 | 305,504 | 246,433 | 124% | |
| 3 | 300,576 | 233,783 | 129% | |
| 4 | 309,844 | 240,641 | 129% | |
| avg | 304,864 | 241,252 | 126% | |
| 500_000 | 1 | 787,313 | 798,618 | 99% |
| 2 | 782,392 | 802,135 | 98% | |
| 3 | 767,072 | 836,073 | 92% | |
| 4 | 766,472 | 844,489 | 91% | |
| avg | 775,812 | 820,329 | 95% |
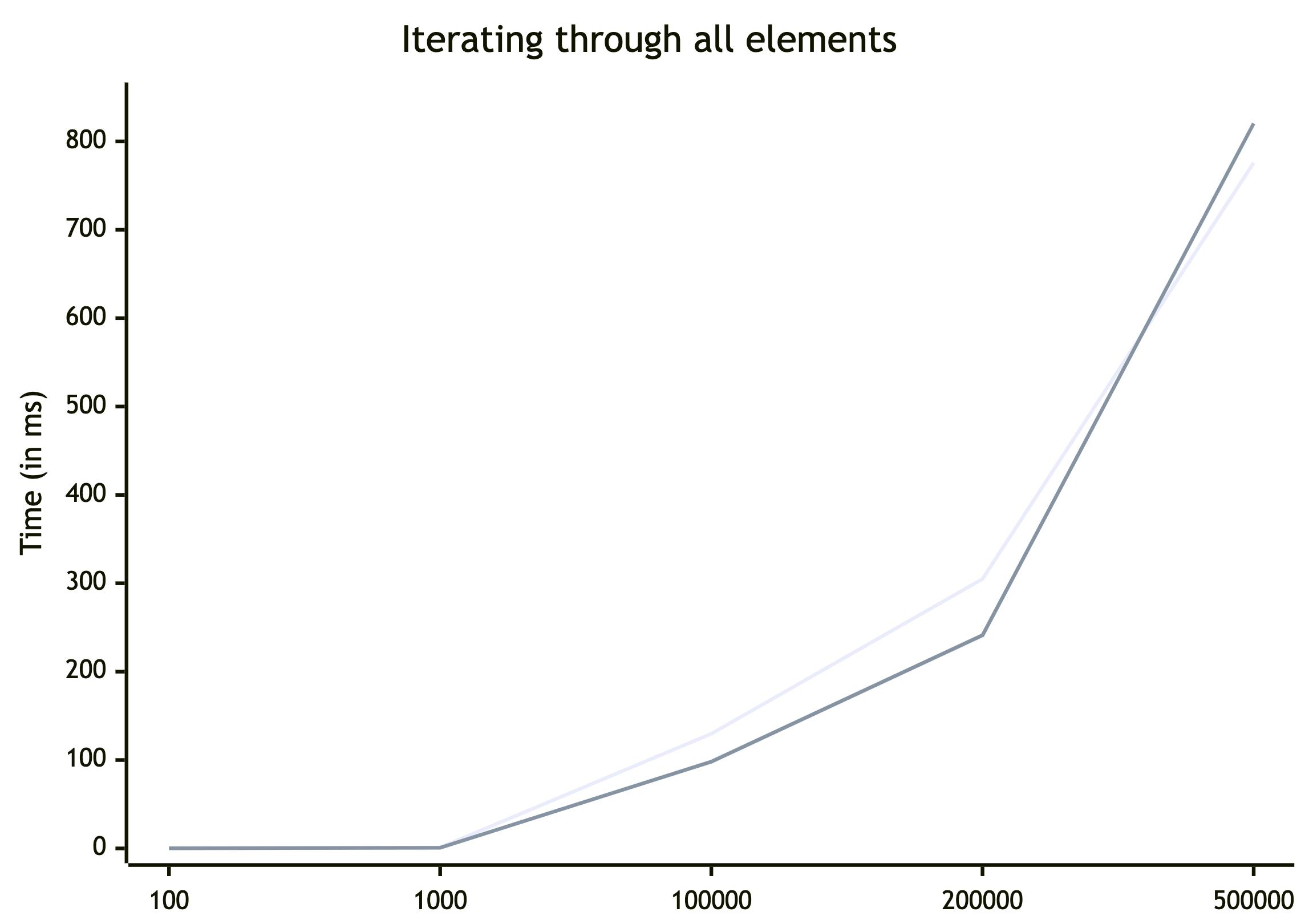
No surprises this time. Map is faster by 22%. But again delete object[key] is a little bit faster, than Map.prototype.delete() for 500k elements.
Memory consumption
This time let’s compare memory consumption. As for key, I’ll use hashed string (to avoid key collisions) and as for values just a string like in tests above. Again, key-value pairs are the same for both Object and Map implementations. For each test there will be 1 iteration, since these are just memory allocations.
| Size | Object (KB) | Map (KB) | Diff (%) |
| 10_000 | 608 | 704 | 86% |
| 100_000 | 12192 | 7024 | 174% |
| 200_000 | 18464 | 14208 | 130% |
| 500_000 | 43056 | 21536 | 200% |
| 1_000_000 | 86064 | 43040 | 200% |
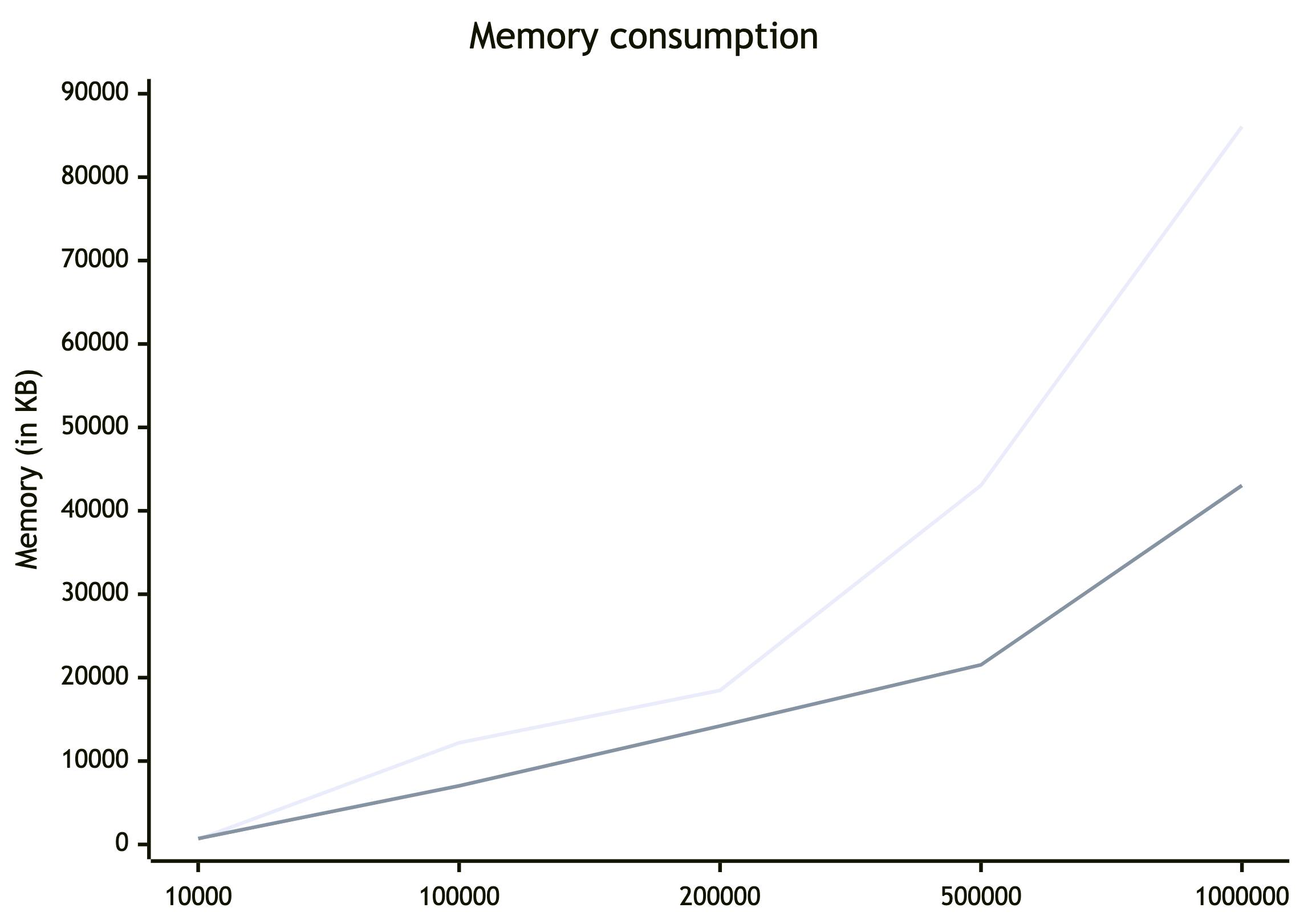
To explain why the numbers are so different, let's dive under the hood.
What’s under the hood?
Object
In the V8 JavaScript engine, an Object is a dynamic collection of properties. To optimize performance, V8 represents objects using hidden classes and inline caching. When an object is created, V8 assigns a hidden class to that object. As properties are added to the object, the hidden class transitions to new hidden classes to reflect the current state of the object.
For example, if we create an empty object:
const x = {};
V8 creates an initial hidden class (C0). If we then add a property to the object:
x.a = 1;
V8 transitions from the hidden class C0 to a new hidden class (C1), which represents an object with property a. This system allows V8 to use the hidden class of an object to quickly look up properties and improve the speed of property access.
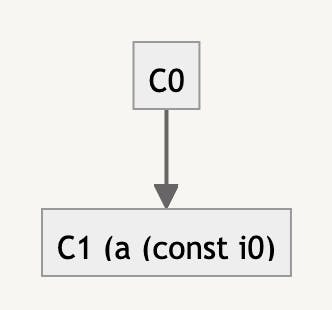
However, this system isn't as efficient when properties are deleted from an object. When a property is deleted, V8 can't revert to the previous hidden class. Instead, it switches to a slower mode of operation where properties are accessed via a dictionary-like data structure. This is why deleting properties from an object is slower compared to other operations.
In addition, since Object is not specifically designed for use as a hash map, it does not have built-in methods for common map operations. As we've seen from our tests, workarounds for insufficient methods can drastically affect performance.
Who can tell more about hidden classes than the V8 developers? Here is a detailed article about the nature of hidden classes in V8.
Map
In contrast, Map uses a hash table data structure underneath. A hash table, also known as a hash map, is a data structure that implements an associative array abstract data type, a structure that can map keys to values. Hash tables use a hash function to compute an index into an array of buckets or slots, from which the desired value can be found. This makes it a fast and efficient data structure for finding, inserting, and deleting data.
Since a classic implementation of a hash map (with a hash function and buckets) doesn't support ordering, a deterministic hash table algorithm is used.
Talking about hash tables we need to mention rehashing. Rehashing is a technique used in hash tables to manage size and efficiency. It is triggered when the load factor (entries divided by buckets) exceeds a certain limit. The process involves:
Creating a larger hash table.
Computing the hash for each entry in the old table based on the new size.
Placing each entry in the new table at the position determined by its hash.
Deallocating memory for the old table.
This ensures efficient operations but temporarily increases memory usage and operation time.
It's interesting that, unlike languages such as Java or Python, the V8 map implementation can not only increase the bucket count on insertion, but it can also decrease the bucket count on deletion. So that, when we actively working with a lot of insertion and deletion we should always keep in mind the two following things:
set()can take O(n) when hash table grows and doing rehashingdelete()can take O(n) when hash table shrinks and doing rehashing
In terms of memory structure, unlike Object, V8 uses a more appropriate single fixed-size array with a header, hash table, and data table. The header stores metadata such as entry count, the hash table stores buckets, and the data table stores entries.
If you want to dive deeper, I’d recommend this article about map implementation.
Summary
To summarize the results of the performance testing, the following can be said:
For insertion of values,
Mapis approximately 4.5-5 times faster thanObject.For checking if a value exists,
MapandObjectshow similar performance.For getting a particular element by key,
MapoutperformsObjectby about 2.8 times.The map's
has()andget()methods take almost the same amount of time, whileObject.hasOwnProperty()is significantly faster thanobject[key].In terms of iterating through all elements,
Mapis approximately 12.8 times faster thanObject.For deleting properties,
Mapis faster by 22%.In terms of memory consumption, both
MapandObjectuse a significant amount of memory, butMapis more efficient.
Obviously, it's highly recommended to use Map for key-value storage in the new code, instead of Object, especially if you work a lot with entry iteration.
Do you need to refactor your Object code to use Map? If you don't use huge maps with a lot of iterations through entries – I'd say to consider a move. But in other cases, definitely not. Again, everything depends on the results of the profiling step.
That's it for today, thank you for your attention. Feel free to write a comment with your favourite JS constructions, and we'll sort out their performance.